
VivaTech 2026 : les LLM ne sont pas le futur et personne ne gouverne ses agents IA
Mon édition spéciale Vivatech 2026, deux jours, trois casquettes

Bonjour à toutes et à tous !
On est désormais 9 000 sur cette newsletter. Merci pour votre fidélité 😊
Si ce n’est pas déjà fait, vous pouvez aussi :
Rejoindre ma communauté Premium en passant à l’abonnement payant.
Gagner en visibilité en sponsorisant cette newsletter.
Découvrir mes formations IA.
Pour la deuxième année consécutive, j’étais média accrédité à VivaTech.
Badge presse autour du cou, mon appli de dictée prête à enregistrer et la question en tête : qu’est-ce qui va compter pour mon secteur et pour vous ?

A VivaTech je porte trois casquettes en même temps :
La juriste qui traque les innovations utiles au droit.
La pilote du projet IA en entreprise qui cherche ce qui pourrait servir à l’agroalimentaire.
Et la créatrice de contenu qui déniche les pépites avant qu’elles soient sur toutes les lèvres.
Résultat : 2 jours de conférences, des rencontres improvisées dans le media lounge, des discussions avec des startups qui m’ont donné des idées concrètes, 30 000 pas et des ampoules aux pieds 😂
Cette édition est dense. Installez-vous, ça va parler souveraineté, agents IA, world models et même robots qui dansent.

VivaTech en quelques chiffres
VivaTech, c’est le plus grand événement d’Europe dédié à l’innovation, à la tech et aux startups.
Cette année, le salon fêtait ses 10 ans à Paris Porte de Versailles, du 17 au 20 juin, avec une édition record :
plus de 200 000 visiteurs issus de 165 pays,
plus de 15 000 startups,
plus de 1 155 speakers.
Emmanuel Macron, le Premier ministre indien Narendra Modi, Jeff Bezos, Yann LeCun étaient sur place.
Et la programmation couvrait cette année l’IA et la productivité, la cybersécurité et la défense, la GreenTech, le spatial et la DeepTech.
Voilà pour le décor. Place à ce que j’en ai retenu.
Qu’est-ce que la souveraineté en IA en 2026 ?
J’ai assisté à une table ronde avec quatre startups françaises qui se revendiquent toutes « souveraines » : Marty AI, Ucontrol AI, Ohaio et Vokse. Au début, je m’attendais à du discours creux, mais j’ai été agréablement surprise.

Selon les intervenants, la souveraineté n’est pas un bloc monolithique. Elle se joue à trois niveaux :
le matériel,
le modèle et
la donnée.
Et selon votre secteur, ce n’est pas le même étage qui compte.
Par exemple, ce qui compte d’abord pour un avocat, c’est la confidentialité et le secret des affaires. Le modèle peut avoir été entraîné aux États-Unis, l’infrastructure peut être américaine, tant que la donnée du client reste localisée et protégée.
C’est une nuance qu’on oublie souvent dans les débats franco-français sur la souveraineté : on confond parfois « souverain » avec « 100 % français à tous les étages », alors que pour beaucoup d’usages professionnels, c’est la localisation et la protection de la donnée qui font la différence.
Deuxième point : la stratégie des « petits modèles ».
Un des intervenants a fait une comparaison simple, celle d’une maison mal isolée. On a découvert une puissance de calcul phénoménale et on l’utilise un peu à tort et à travers. Utiliser un modèle surdimensionné pour résumer un texte, c’est comme chauffer une maison non isolée.
Le bon réflexe, c’est d’utiliser le bon modèle pour la bonne tâche. Ça réduit les coûts, l’impact environnemental et ça permet de faire tourner des modèles plus petits en local, donc plus simples à sécuriser.
Dernier point, sur les PoC. Un des fondateurs a dit une phrase que je vais réutiliser en formation : on ne peut pas se permettre de dire à un PoC « on s’en fiche, on met de la donnée fictive ». Un PoC qui ignore dès le départ la sécurité, le coût réel et l’intégration aux systèmes existants n’est pas une étape vers la production, mais une impasse.
Si vous pilotez ou validez des projets IA dans votre entreprise, c’est le genre de question à poser dès le cadrage : ce PoC est-il pensé pour grandir ou juste pour faire une démo ?
Pourquoi les agents IA posent un problème de gouvernance avant un problème technique
Deux sessions m’ont confirmé une inquiétude que j’ai déjà partagée ici : on crée des agents IA plus vite qu’on ne sait les gérer.
Beaucoup d’entreprises ne savent pas combien d’agents IA existent chez elles.
La réponse proposée par AvePoint lors d’une masterclass chez Microsoft : un modèle de responsabilité partagée.
Le métier qui crée l’agent doit pouvoir justifier qu’il en a toujours besoin, le faire évoluer ou le faire archiver.
L’IT fournit le cadre et les outils, mais ne décide pas seul de la pertinence d’un agent métier. Et chaque agent devrait avoir un cycle de vie complet : création justifiée, monitoring, revue périodique, décommissionnement quand il devient obsolète.
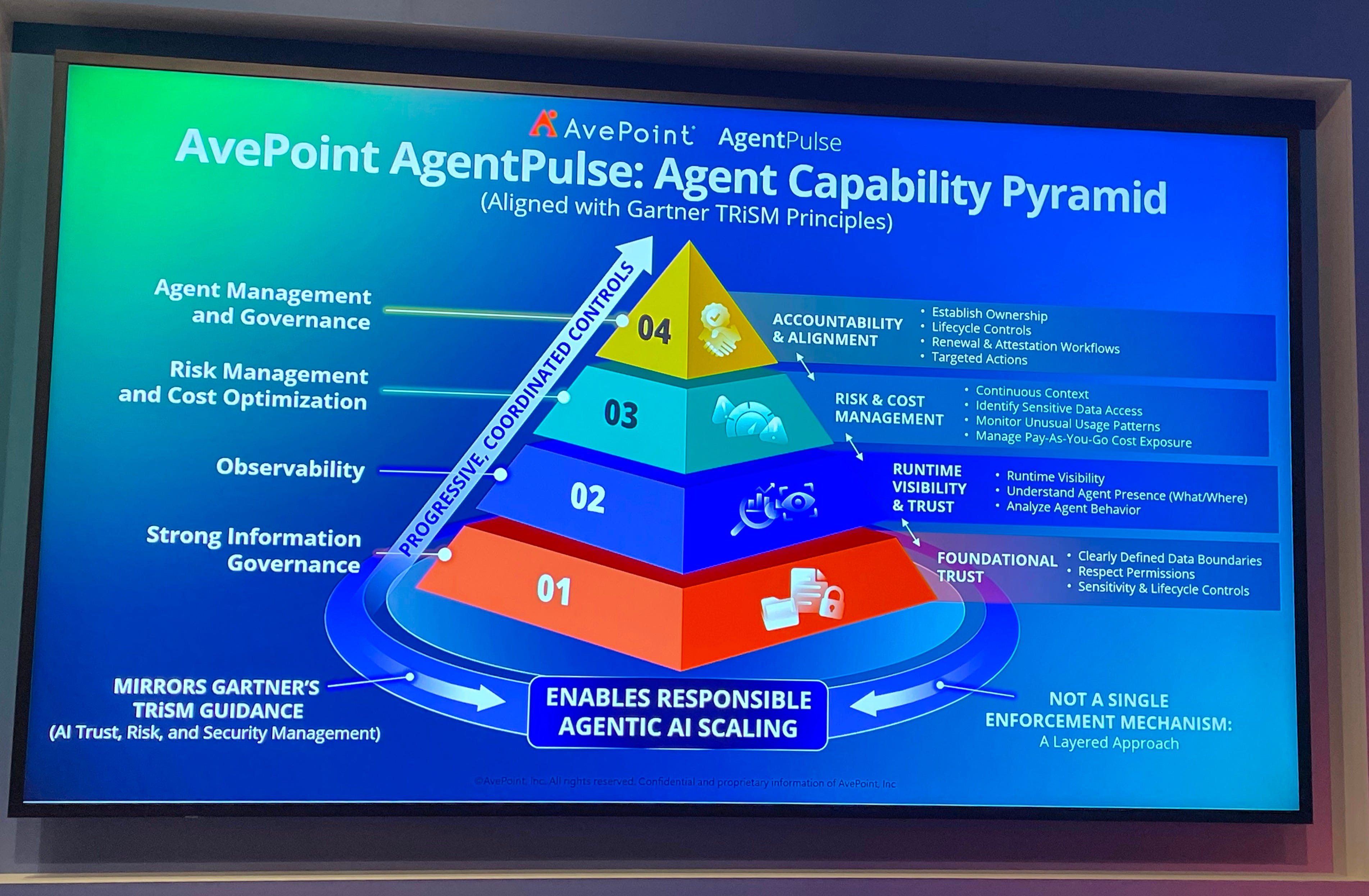
Vu depuis mon poste de juriste, ça touche à des sujets très concrets.
Qui est responsable juridiquement d’un agent créé par un commercial un peu trop motivé ? Qui répond si cet agent a eu accès à des données qu’il n’aurait pas dû voir ?
Sans inventaire et sans cycle de vie documenté, ces questions n’ont pas de réponse claire le jour où ça pose problème.
La deuxième démonstration, plus concrète, montrait un agent IA configuré pour répondre à des questions sur des chantiers de construction, à partir de fichiers Excel disparates et mal structurés, connectés via OneDrive. Aucune ligne de code, tout en langage naturel, y compris pour expliquer à l’agent comment faire le lien entre une colonne « identifiant employé » d’un fichier et une colonne « code travailleur » d’un autre.
Le résultat était impressionnant sur la rapidité de mise en œuvre, mais le présentateur a été honnête (je l’en remercie) : « c’est une démo, ce n’est pas prêt pour la production ». Trois chantiers restent à couvrir avant la prod : fiabilité sur des données réelles, passage à l’échelle sur des gros volumes, gouvernance sur qui possède quelle donnée et qui peut y accéder.
Alors on voit que la technique pour créer un agent est devenue presque triviale. La gouvernance, elle, reste un chantier humain et organisationnel.
Et c’est précisément là que, en tant que juristes, on a un rôle à jouer avant que ça devienne un sujet de crise.
Pourquoi Yann LeCun pense que les LLM ne mènent pas à l’intelligence générale
La session une des plus attendues du salon, sans doute. Salle bondée, file d’attente dehors, applaudissements nourris à son arrivée. Le niveau d’attente m’a rappelé celui réservé à Jeff Bezos la veille.

Pour Yann LeCun, les grands modèles de langage sont utiles, mais ils ne mènent pas à une intelligence de niveau humain, parce qu’ils manipulent des séquences de texte alors que le monde réel n’en est pas une.
Yann LeCun, fraîchement parti de Meta après avoir dirigé la recherche IA pendant des années, est venu défendre cette thèse à contre-courant de pratiquement toute l’industrie. Il insiste : les LLM ne sont pas mauvais, ils sont même très utiles pour traduire, coder, écrire.
Il a une formule pour ceux qui pensent que la simple mise à l’échelle des LLM mènera à la superintelligence : « LLM-pilled ». Une forme de croyance, selon lui, qui a créé une monoculture dans l’industrie, où la peur de prendre du retard empêche d’aller chercher d’autres pistes.
Sa réponse s’appelle JEPA, pour Joint Embedding Predictive Architecture.
L’idée : au lieu de générer du texte token par token ou de tenter de prédire une vidéo pixel par pixel (un problème qu’il qualifie de mathématiquement insoluble), le système apprend des représentations abstraites du monde et prédit l’évolution de ces représentations. La brique de base de ce qu’il appelle les « world models », des systèmes capables d’anticiper les conséquences d’une action avant de l’exécuter.
C’est ce paradigme qui l’a poussé à quitter Meta pour fonder sa propre société, AMI (Advanced Machine Intelligence) Labs.
Meta a recentré ses efforts sur les LLM et le rattrapage du reste de l’industrie, l’ambiance est devenue moins favorable à la recherche fondamentale de long terme qu’il voulait mener.
Yann LeCun a aussi défendu l’open source avec une comparaison qui ne laisse pas indifférent.
Fermer l’accès aux modèles les plus avancés sous prétexte de dangerosité, c’est, selon lui, se comporter en « obscurantiste médiéval ». Il a même visé directement des entreprises comme Anthropic, qu’il accuse de vouloir garder le contrôle sous couvert de sécurité.
C’est dans cette logique qu’il a présenté Tapestry, un projet hébergé par l’AI Alliance, visant à construire un modèle de fondation mondial et open source, entraîné de façon fédérée.
Chaque pays ou institution contribue avec ses propres données et infrastructures, sans avoir à les partager directement, le partage se faisant au niveau des paramètres du modèle.
Ce que j’en retiens, avec ma casquette juridique : si la prochaine génération d’IA raisonne sur des représentations du monde plutôt que sur du texte, les outils juridiques qu’on connaît aujourd’hui (résumé, recherche, rédaction assistée) ne sont qu’une étape de départ.
Et avec ma casquette plus sceptique : AMI Labs vient de lever plus d’un milliard de dollars en mars. Le discours est clair et ambitieux, la preuve par les faits reste à venir.
Pourquoi le matériel reste le vrai goulot d’étranglement de l’IA
Une session que je n’attendais pas forcément m’a servi un rappel utile : toute cette intelligence artificielle repose sur des machines qu’on ne voit jamais. Et la pénurie n’est pas près de se résorber.
Pendant des décennies, la loi de Moore disait qu’on doublait le nombre de transistors sur une puce tous les deux ans. Pour l’IA, ce rythme ne suffit plus : il faut désormais le multiplier par dix.
C’est Jensen Huang, le patron de NVIDIA, qui pose ce nouveau repère.
Et ça veut dire beaucoup plus de puces, donc beaucoup plus de plaquettes de silicium à produire pour chaque génération de matériel. Le prochain produit phare de NVIDIA, prévu pour 2027, en demandera cinq fois plus que la génération actuelle. Soit 250 plaquettes pour un seul produit.
Ces plaquettes sont fabriquées avec des machines de lithographie EUV, qui « impriment » les puces les plus avancées au monde.
Un seul fabricant les produit : le néerlandais ASML, qui détient le monopole de cette technologie. Et c’est le patron d’ASML qui est venu parler de ça sur le scène de Vivatech.
La précision de ces machines donne le tournis. Les motifs gravés font 8 nanomètres, des milliers de fois plus petits qu’un cheveu humain. Les miroirs qui dirigent la lumière sont mille fois plus précis que ceux du télescope Hubble, l’équivalent de viser une pièce de monnaie posée sur la Lune depuis la Terre.

Et le détail qui m’a fait sourire : la lumière utilisée pour cette gravure n’existe pas naturellement sur Terre. Elle est créée en tirant un laser sur des gouttelettes d’étain, chauffées à 220 000 degrés.
On parle souvent d’IA « dématérialisée ». Derrière il y a pourtant de la physique extrême et une chaîne de production sous tension.
Une autre conférence, côté infrastructure cloud, posait une question voisine : faut-il des puces généralistes ou spécialisées pour l’IA ?

Réponse donnée : les deux, en portefeuille. Les puces généralistes restent flexibles face à des modèles qui évoluent vite. Les puces spécialisées, conçues pour une tâche stable, peuvent offrir dix fois plus de performance, au prix d’un risque si le besoin change en cours de route.
Le même raisonnement vaut pour l’informatique quantique et j’en ai eu la confirmation sur le stand IBM, où j’ai croisé le « chandelier quantique », un système de refroidissement pour ordinateur quantique.

Une technologie capable de résoudre des problèmes inaccessibles aux machines actuelles. Horizon de commercialisation : 2029.
L’ingénieur d’IBM qui présentait le système a été clair : le calcul quantique n’a pas vocation à répondre à tous les usages du quotidien.
Son intérêt se concentre sur des cas précis, simulation médicale, recherche, optimisation complexe, là où les besoins de calcul sont massifs et le problème bien posé.
En l’écoutant, je me suis dit que le même principe s’applique en direction juridique et en entreprise en général. On a tendance à vouloir un seul outil pour tout faire. La vraie maturité, que ce soit pour le quantique ou pour l’IA générative, c’est de savoir identifier les cas où la puissance est justifiée, et ceux où elle ne l’est pas.
Si la précision et la puissance se jouent dans des machines qu'on ne voit jamais, à VivaTech l'IA la plus visible avait un visage ou presque.
Il faut qu'on en parle, parce que tout le monde en a parlé.
Et les robots humanoïdes dans tout ça ?
Cette année les robots humanoïdes ont eu un succès sur le salon.
Files d’attente, applaudissements. Et oui, je l’avoue, j’ai sorti mon téléphone moi aussi pour filmer leur petite chorégraphie synchronisée.

Pour l'instant, ce qu'on a vu en majorité, c'est de la danse.
Bluffante techniquement, mais on reste loin de l'agent physique capable de faire plus qu'un show bien réglé.
Et la vidéo qui a le plus circulé sur les réseaux ces derniers jours le confirme à sa façon : sur le stand de RebuilderAI, deux robots Unitree G1 ont reculé un peu trop loin pendant leur chorégraphie et ont envoyé valser les écrans installés derrière eux.
La vraie question, celle qu'on se posera probablement à l'édition 2027 : ce que ces robots sauront faire au-delà de la chorégraphie.
Pour conclure
Deux jours, trois casquettes, beaucoup de marche, un constat qui traverse toutes les sessions : la technique avance plus vite que notre capacité collective à la gouverner, que ce soit au niveau d’un agent IA créé par un collaborateur ou d’un modèle de fondation mondial.
Etiez-vous à VivaTech cette année ? Qu’est-ce qui vous a marqué ?
Si cette newsletter vous est utile
Cliquez sur le ❤.
Parlez-en autour de vous.
Et si vous voulez soutenir ce travail, la version Premium existe.
À très vite,
Daria
Merci pour cette review complète. Ça donne un bon aperçu de ce qui s'est passé à Vivatech cette année!
Comment tu fais pour rédiger des éditions aussi intéressantes ? Merci encore !